The 54% to 21.5% Problem
The backtest showed a 54% win rate. Live trading produced 21.5%. A 32.5 percentage-point divergence does not come from luck or regime change. Three concrete root causes, and why alignment tests should be a deploy gate on every scoring system.
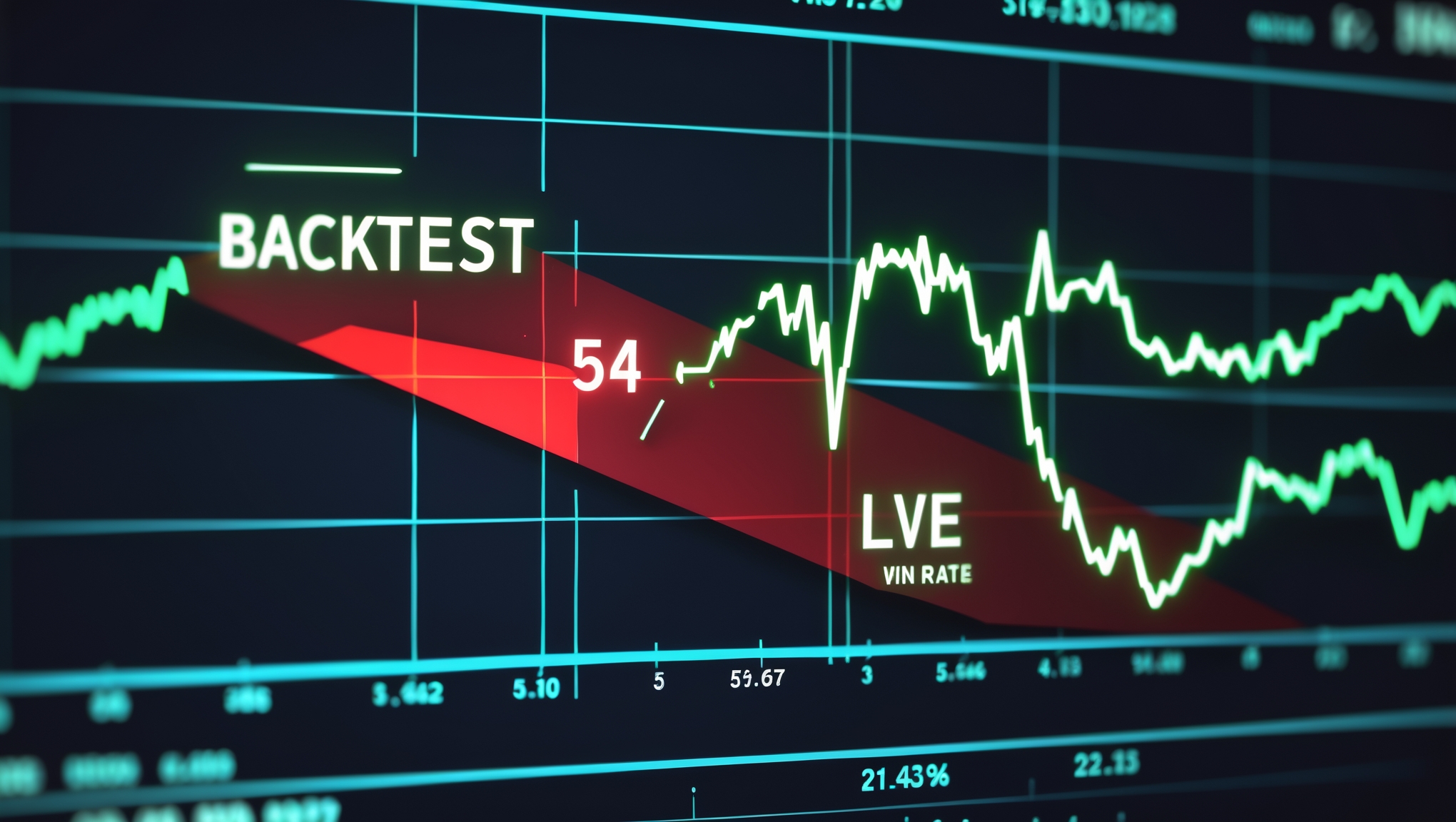
The InDecision signal engine backtested at a 54% win rate. When it went live, it produced 21.5%.
Thirty-two and a half percentage points of divergence. That is not noise. That is not a regime shift. That is not the market being harder than the backtest. That is three concrete, fixable bugs, each of which was invisible in the backtest environment and each of which became load-bearing the moment real capital was at stake. The gap between the two numbers is not a mystery. It is a diagnostic story, and every live-trading system I have ever shipped has had a version of it.
This post is that diagnostic story. Three root causes, what each one looked like, and the alignment-test pattern that should have caught them before the engine ever saw real capital.
Root Cause #1: Fail-Open Defaults Producing Phantom Signals
The scoring engine had graceful-failure logic. When a component failed to produce a value — an API timeout, a parse error, a missing row — the component returned a safe default instead of blocking the whole signal. In the backtest environment, where every component had clean historical data, the defaults almost never fired. Every signal in the backtest had every component contributing real values.
In the live environment, defaults fired constantly. APIs timed out. Rate limits hit. Parsers failed on unexpected market formats. The engine kept producing signals — because graceful failure was how it was designed — but the signals were contaminated with default values that were never meant to flow into a production decision.
The backtest had never exercised the default path in bulk. The live environment exercised it on a huge fraction of signals. The scoring engine was effectively running a different rubric in production than the one it had been backtested on. And the difference was entirely in the tail: the signals where components failed to resolve produced the phantom trades, and the phantom trades produced most of the losses.
The fix was to make "default" visible. Any signal where more than one component had fallen to a default value was flagged as degraded and excluded from capital allocation. The engine still scored them. It still logged them. It just did not trade them. Fail-open was preserved for monitoring but removed from the execution path.
Root Cause #2: Conviction Labels Misaligned With Outcomes
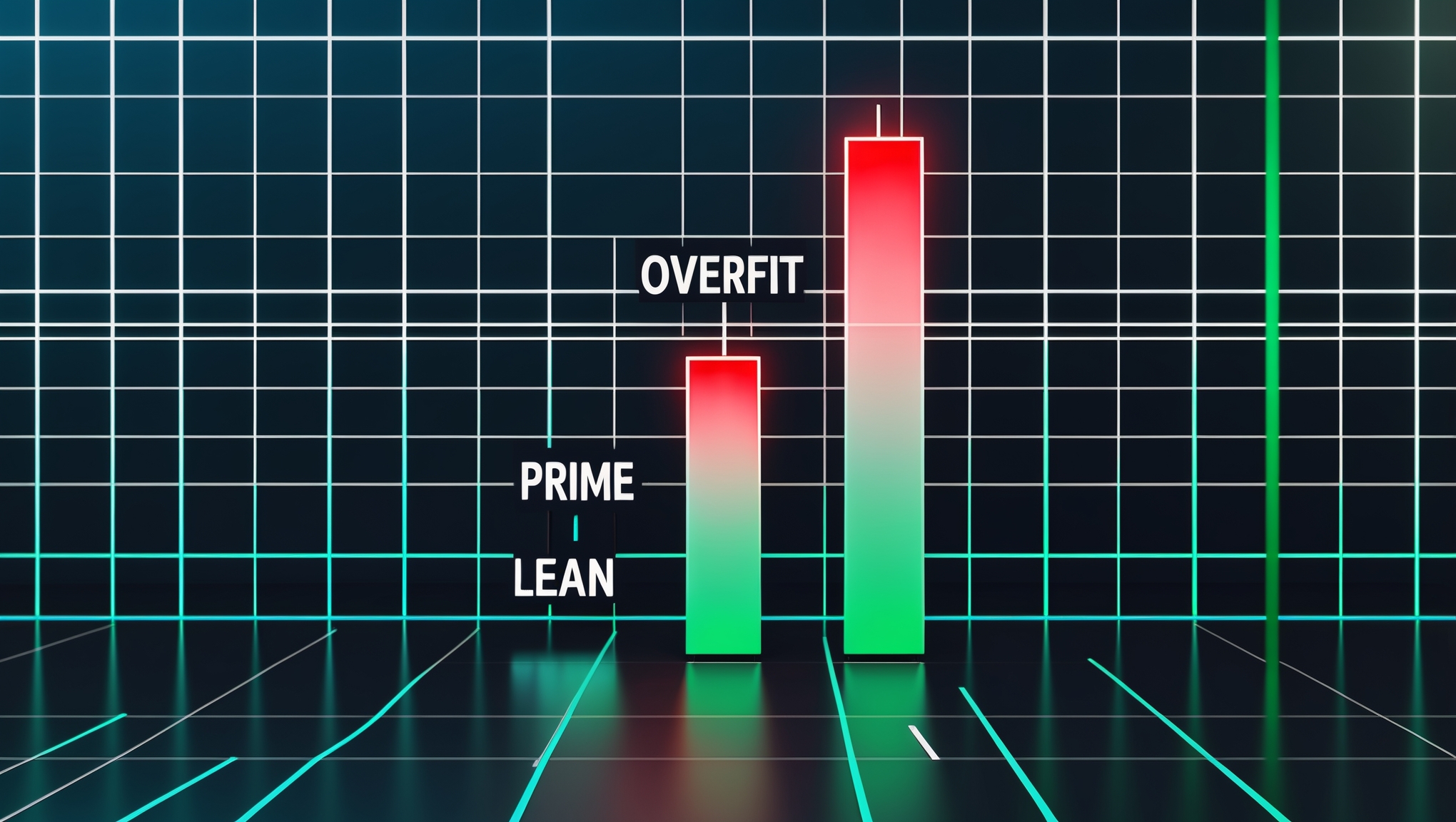
The second root cause was the conviction hierarchy inversion. The engine shipped with three tiers: OVERFIT (strongest), PRIME (moderate), LEAN (weakest directional). The backtest reported strong aggregate performance because the overall numbers looked good — 54% win rate, positive expectancy, acceptable drawdown.
What the backtest report did not show was the per-tier breakdown. When we finally ran that breakdown against live outcomes, the hierarchy was inverted:
- OVERFIT: 49.4% win rate, negative PnL
- PRIME: 63.9% win rate, positive PnL
- LEAN: 75.0% win rate, positive PnL
The aggregate 54% win rate was masking the fact that the highest-capital-scaling tier was actually the worst performer. Because OVERFIT signals got scaled capital, their losses dominated the portfolio. The backtest's aggregate number was technically true but operationally misleading. The tier that the engine trusted most was dragging the entire portfolio down.
The fix was not in the math. The fix was in the labels. OVERFIT got suppressed entirely. PRIME became the capital-scaling tier. LEAN was enabled with fixed sizing. Nothing about the rubric changed. Only what we were willing to let capital follow changed.
This is the lesson that deserves a full paragraph of its own: aggregate performance metrics hide per-tier inversions. A 54% aggregate win rate can coexist with a strongest-tier win rate below 50%, and the difference matters because capital scaling amplifies the worst bucket. Every conviction tier must be validated against outcomes independently. Aggregates lie about the distribution.
Root Cause #3: Live-Only Data Quality Issues
The third root cause was the category I find hardest to defend against: bugs that only exist in the live environment because the backtest environment cleaned them up.
The backtest used historical market data that had been snapshotted and post-processed. Weird records had been filtered. Parser edge cases had been resolved. Malformed markets had been excluded. The dataset was cleaner than anything the engine would ever see in production. Every signal in the backtest had well-formed inputs.
In the live environment, the engine pulled markets directly from upstream APIs. Forty-one percent of markets were discarded as unparseable — twelve of twenty-nine NBA markets on the first day I measured. The engine kept working, but it was working on a non-random sample of the market universe. The backtest had never seen the 41% parser-failure rate because the backtest had been built against a post-filtered dataset.
This is why parser coverage rate should be a tracked metric on every live scoring system. It does not need to be at 100%. It needs to be monitored, so that a drop from 90% to 60% fires an alert before it corrupts a week of trading. Parser coverage is a data-quality metric disguised as an engineering metric. It belongs on the dashboard with win rate and PnL, not buried in a log file.
The Alignment Test Pattern
All three of these root causes have something in common. They were invisible in the backtest and obvious in live trading because the backtest environment was cleaner than the production environment in ways the backtest did not know to disclose. This is the core problem that every backtest/live validation system has to solve.
The pattern I now run before any scoring system goes live is straightforward. Call it an alignment test, and think of it as a deploy gate:
- Run the live engine in shadow mode for a week. The engine computes every signal it would have computed, logs every decision it would have made, but does not allocate capital. You now have a live-environment dataset generated under live-environment conditions.
- Recompute the backtest using the shadow-mode dataset. Same scoring rubric, same rules, just against the messier real-world inputs. The backtest number will fall. The question is: how far does it fall?
- Investigate every component of the drop. Fail-open fire rate. Per-tier win rate. Parser coverage. Default contamination. Any gap of more than five percentage points between the clean backtest and the shadow backtest is a bug waiting to happen.
- Only promote to live capital after the shadow backtest converges. The deploy gate is not "backtest shows 54%." The deploy gate is "shadow backtest shows 54% on live-environment data." If you cannot produce a live-environment backtest, you do not have permission to spend real capital. Not yet.
The InDecision engine now runs this test on every scoring change. The deploy gate is a passing alignment test, not a passing unit test suite. Unit tests verify that the code does what the spec said. Alignment tests verify that the spec was describing reality. The same pattern is now a hard requirement across every scoring system in the broader Jeremy Knox engineering stack — no exceptions, no grandfathered bots.
Closing Thought
A 32.5 percentage-point drop from backtest to live is not an accident. It is a message. The backtest was telling you what the engine would do on a version of reality that does not exist. Your job is to test the engine against the version of reality that does. If you do not have a mechanism to do that before you risk capital, you do not have a backtest. You have a unit test with a fancy name.
The painful finding from this session was not that the live win rate was 21.5%. It was that the tools required to catch the drop before it happened already existed. Every component value was stored. Every signal was logged. Every outcome was recorded. We could have run the alignment test on day one. We did not run it because nothing forced us to. Now it is a deploy gate, and no scoring change ships to live capital without passing it.
If your backtest and your live results disagree by more than a rounding error, the backtest is wrong. Find out why before the divergence finds your capital.
Explore the Invictus Labs Ecosystem

// FOLLOW THE SIGNAL
Follow the Signal
Stay ahead. Daily crypto intelligence, strategy breakdowns, and market analysis.
Get InDecision Framework Signals Weekly
Every week: market bias readings, conviction scores, and the factor breakdown behind each call.